I.Matmul学习笔记
补充学习资料
https://hao-ai-lab.github.io/cse234-w25/karpathy/nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs.代码来源官方文档
stride
stride[i] = 在第 i 个维度上索引 +1,底层一维内存地址要跳多少格。
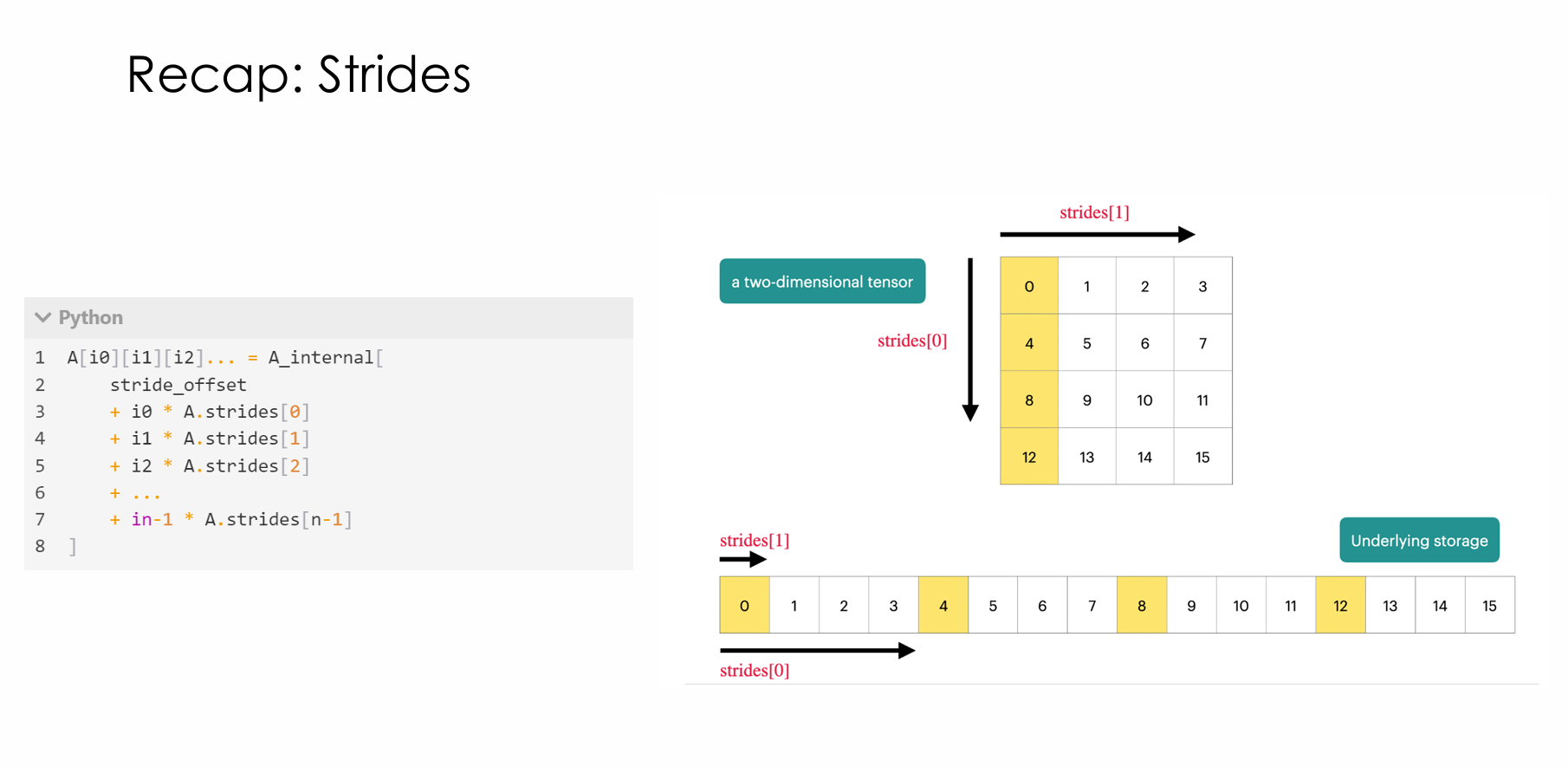
二维的例子,行连续存储stride[1],列每增加1,存储号增加4,stride[2]为4. 下面这道题目更加便于理解

这就是每从一个维度增加1,就增加对应维度的stride数目。
matmul
&A[m : m+BLOCK_SIZE_M, k:k+BLOCK_SIZE_K] = a_ptr + (m : m+BLOCK_SIZE_M)[:, None]*A.stride(0) + (k : k+BLOCK_SIZE_K)[None, :]*A.stride(1);
&B[k : k+BLOCK_SIZE_K, n:n+BLOCK_SIZE_N] = b_ptr + (k : k+BLOCK_SIZE_K)[:, None]*B.stride(0) + (n : n+BLOCK_SIZE_N)[None, :]*B.stride(1);a_ptr就是stride_offset,然后 (m : m+BLOCK_SIZE_M)是一个向量:[m,m+1,...,m+BLOCK_SIZE_M],通过[:, None]增加一个维度,乘上行方向上的stride,变成行方向的偏移。列方向同理,如
行偏移:
[[16],
[24],
[32]]
列偏移:
[[0, 1, 2, 3]]然后两个向量相加时自动广播,一个列向量 [M,1] 和一个行向量 [1,N] 相加,会广播成一个 [M,N] 的矩阵。
广播
这个和利用stride=0进行广播没有关系,用stride=0进行广播是利用了zero-copy所作的
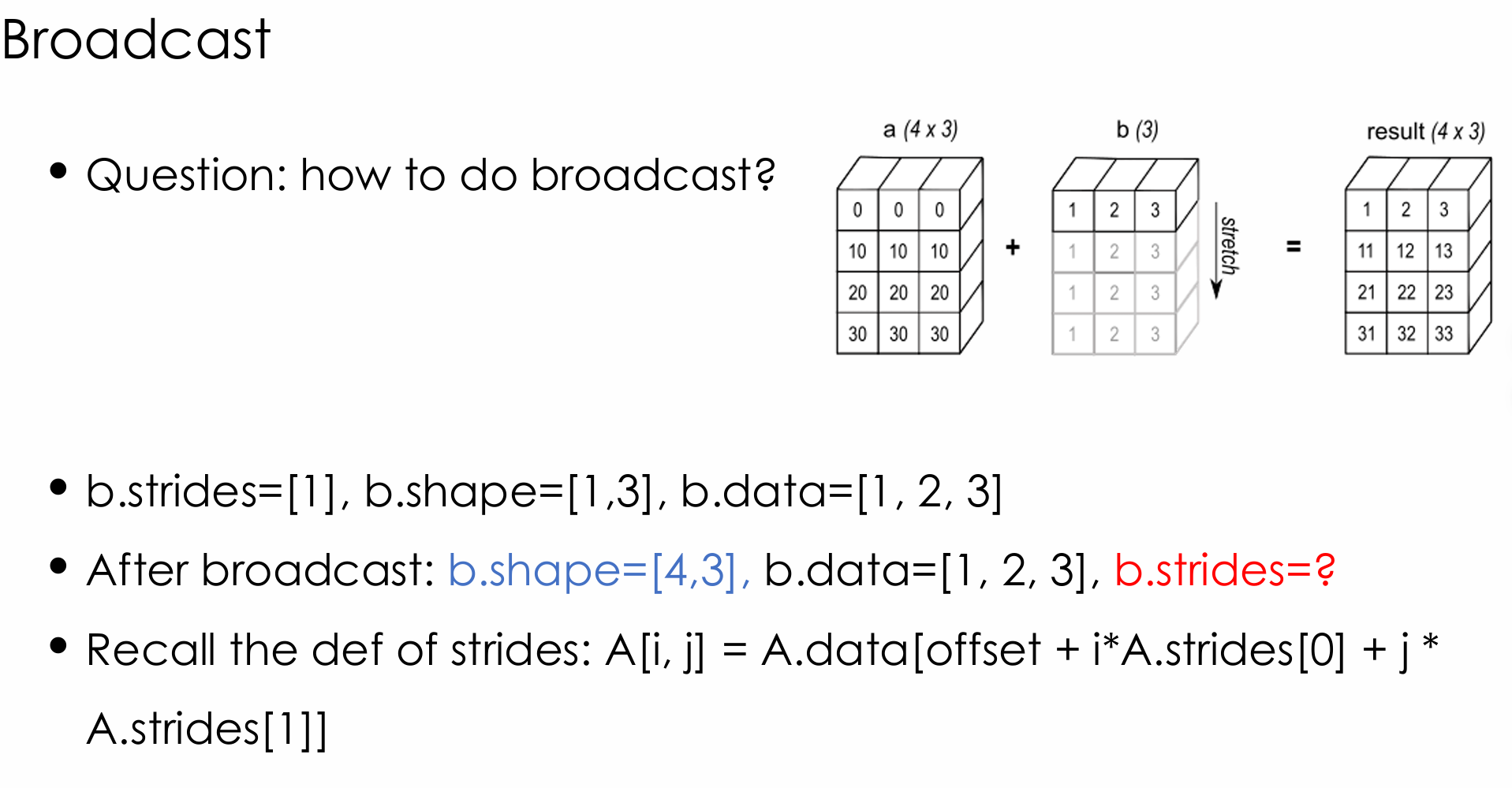
然后后面a_ptrs算的是[M,K]的一小块的矩阵地址号,具体算法就和上面差不多了
offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + (offs_am[:, None]*stride_am + offs_k [None, :]*stride_ak)
b_ptrs = b_ptr + (offs_k [:, None]*stride_bk + offs_bn[None, :]*stride_bn)其中有一点pid本是一个线程自己的pid,但是需要映射成两个来分别算横纵坐标,一般这么算
pid = tl.program_id(axis=0) # kernel[grid](...) 中grid就是axis=0中的一维编号
grid_n = tl.cdiv(N, BLOCK_SIZE_N)
pid_m = pid // grid_n
pid_n = pid % grid_n直观的逻辑是这样:
pid:
pid_n=0 pid_n=1 pid_n=2 pid_n=3
pid_m=0 0 1 2 3
pid_m=1 4 5 6 7
pid_m=2 8 9 10 11后面的update部分就是在更新指针到下一个块。
a_ptrs += BLOCK_SIZE_K * stride_ak;
b_ptrs += BLOCK_SIZE_K * stride_bk;L2 Cache Optimizations
后面就看不太懂了……先去把这一节课后面部分听一下jan16.pdf,然后再来
Matmul deep dive
最基础的矩阵乘法结构是三层循环

更换为块状的乘法后类似与后面我们计算的方法,这是寄存器级别的优化,v1*v3 + v2*v3 + v1*v2需要少于ALU中包含的寄存器
- register tiled Matrix Multiplication
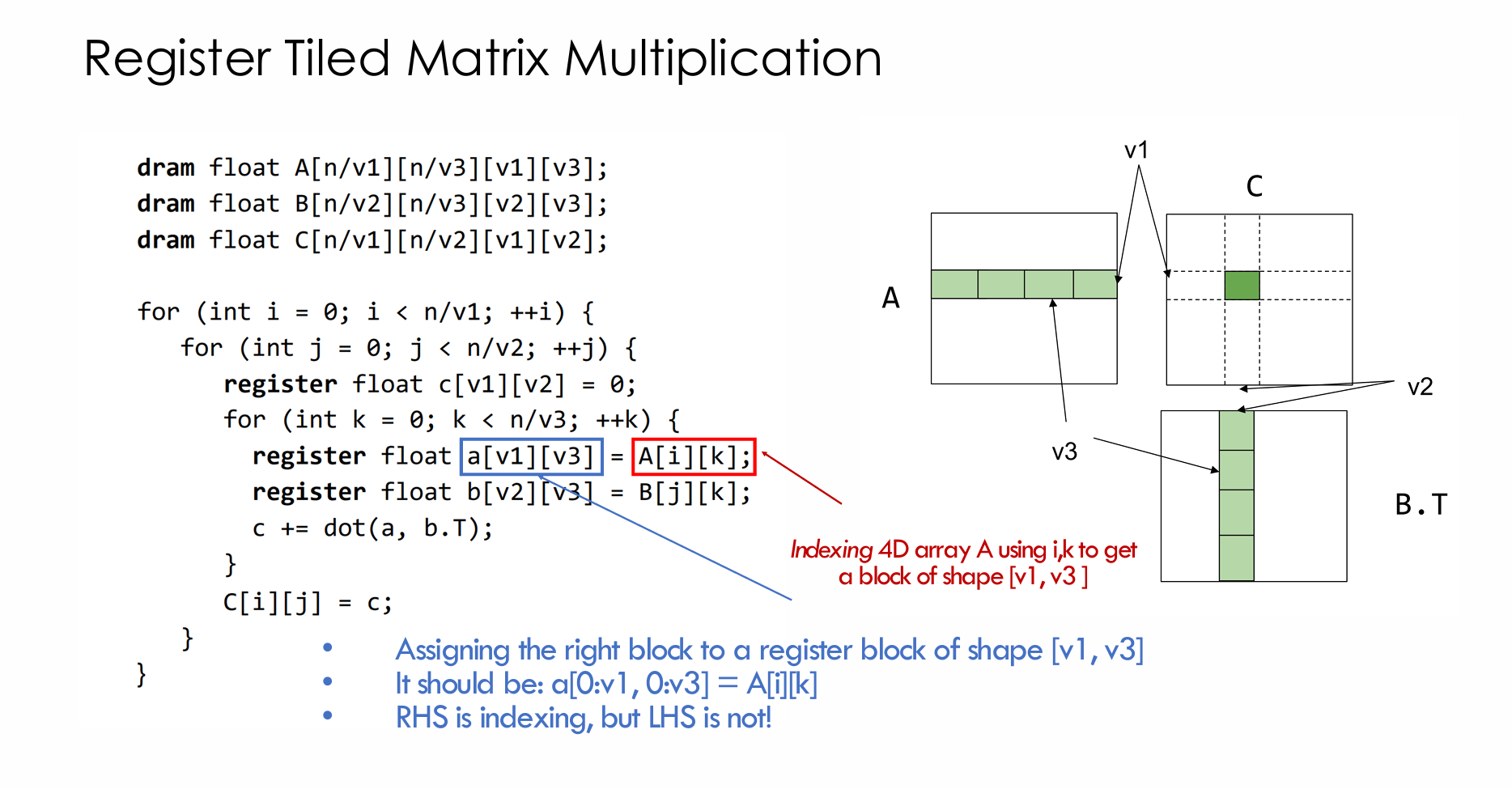
但是这个c+=dot(a,b.T)其实还是加了个点乘进去,不过全在寄存器里面。 读的次数减少了是因为循环少了变成,然后读a的时候要乘 ,读b同理。 它快的本质就是空间换时间,用寄存器/片上存储换 DRAM bandwidth。相比只用3个寄存器的版本,load一次的数据会被更高效的利用,也就是不会再被反复读取来计算,IO的总次数少了。
- Cache-aware tiling
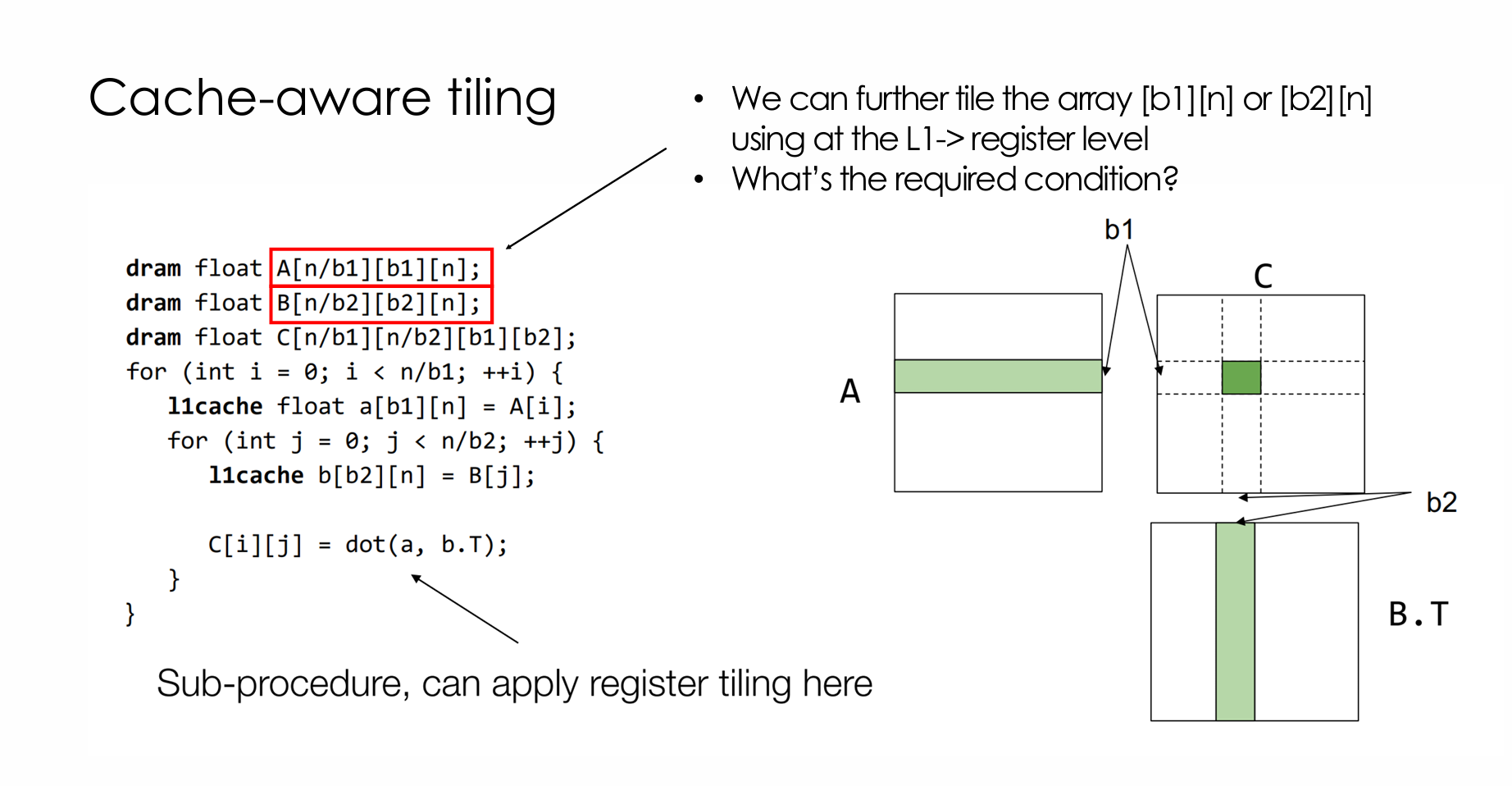
此处可理解为矩阵切成长条后点乘,比起上一个tile是求和的,这个少了一层循环。中间的点乘比较小,就可以拿来reg-tiling,这里本来是有个v3的,但是v3不重要(在前面的复杂度中抵消了),就直接取1了。 下面是一个两种方法都用的matmul例子

到这里基本上就可以理解这个cache optimization了,然后接着来看教程
这里讲的又和上面的io次数好像关联不大了,是load数据重复使用的问题了,而不是算法。
若是Row-major ordering,计算顺序是(0,0), (0,1), (0,2), ..., (0,8), (1,0), (1,1), ...,此时行A的复用率很高,每一次都是使用的0,而B每次都切换,没有产生cache命中。这就是要用group ordering的原因
num_pid_in_group = GROUP_SIZE_M * num_pid_n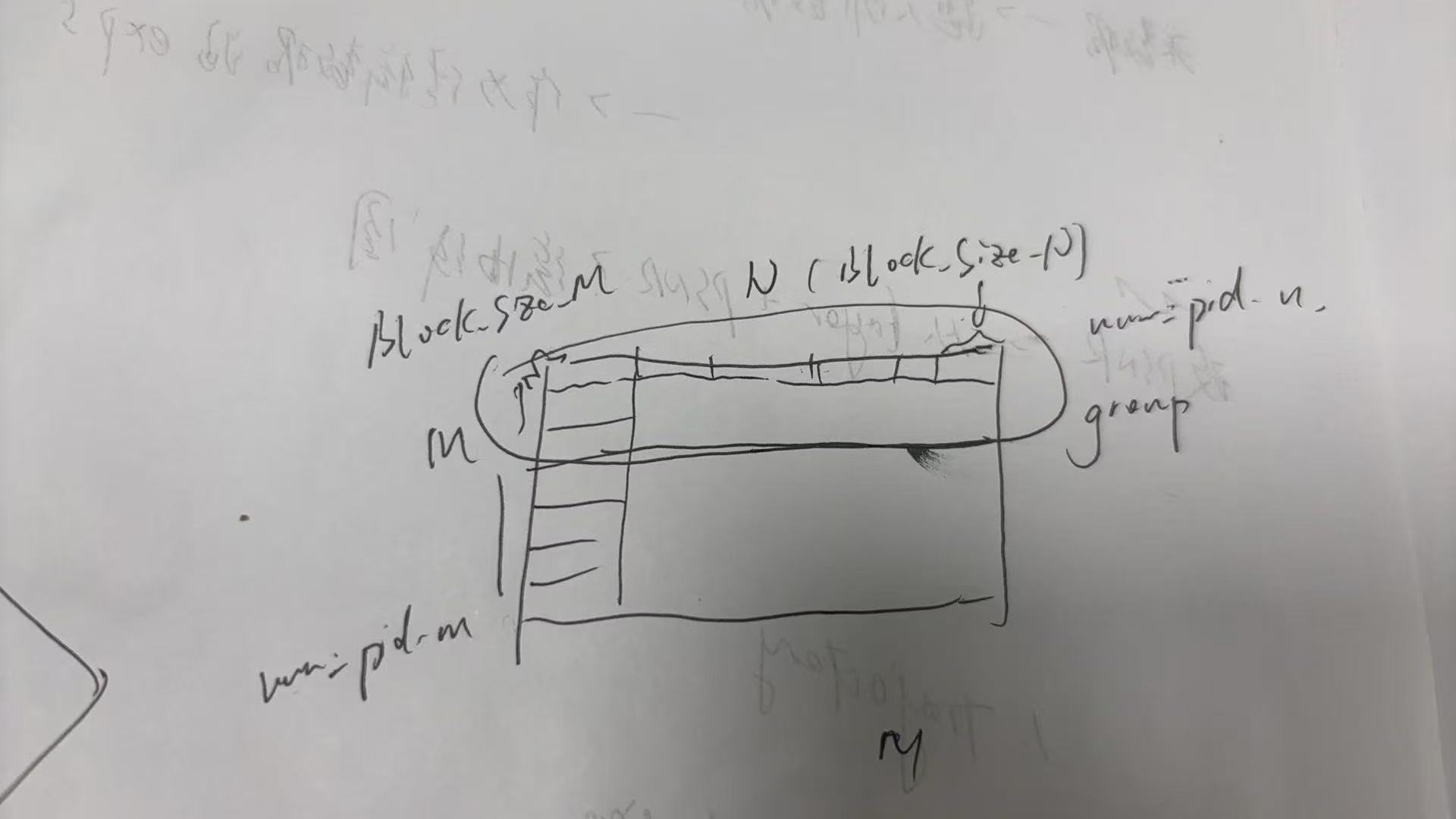
- 此处的意思是一个 group 里面一共有多少个 program / block
GROUP_SIZE_M是一个 group 里包含多少行 block- 一个 group 的形状是
- 行方向:只取
GROUP_SIZE_M行 - 列方向:取完整的
num_pid_n列
- 行方向:只取
- num_pid_in_group为总数
# *Within groups*, programs are ordered in a column-major order
# Row-id of the program in the *launch grid*
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
# Col-id of the program in the *launch grid*
pid_n = (pid % num_pid_in_group) // group_size_mpid % num_pid_in_group是当前线程在group内部的编号% group_size_m是防止越界pid_n是因为编号是竖着增长的
0 3 6
1 4 7
2 5 8